Product Features
Data Storage
Cache Acceleration Solution
A cache acceleration solution typically uses SSD-based caching devices to accelerate the data access for HDD data disks. ZStack ZStone uses high-speed SSDs through the ZAS cache module to provide I/O caching for traditional HDD devices. The ZAS cache module caches frequently accessed hot data in the high-speed SSD devices and returns it to the application, significantly improving I/O performance, especially in scenarios characterized by hot data access patterns.
The ZAS cache module supports two caching policies: Writethrough and Writeback. In Writethrough mode, data is written simultaneously to the cache and the backend storage device, ensuring data consistency. In Writeback mode, most of the cache is used to buffer write data, ensuring that dirty data is written sequentially to the backend storage device. The system disables the Writeback policy by default but you can switch caching policies at runtime.
- Flexible Cache Data Migration
The ZAS cache module automatically migrates data from slow disks to the SSD cache based on data access frequency and heat to improve access speed for that data. Simultaneously, based on cache usage and available cache space, the module automatically migrates less frequently used data from the SSD cache to slow disks to free up cache space.
- Data Protection
If a data I/O error occurs on the flash device, the ZAS cache module first attempts to read from the disk to recover the data or marks the cache entry as invalid. For unrecoverable errors, such as those involving metadata or dirty data, the cache module automatically disables caching.
Automatic Thin Provisioning
Before data is written to the logical volume, thin provisioning provides upper-layer applications with more virtual storage space than what is physically available in the storage cluster. This offers convenient scalability and improves storage space utilization efficiency.
Storage Pool Recovery QoS
QoS (Quality of Service) is a technology used to address I/O resource allocation issues. It helps you throttle I/O read and write speeds, facilitating the rational allocation of resources.
Within data nodes, an op_shardedwq queue handles various I/O requests from the upper level. This is a composite queue, typically containing several sub-queues. After I/O requests are dequeued, they interact with the disk via the ObjectStore interface. I/O types fall into two main categories: business read/write I/O requests from clients, and I/O generated by internal activities of the storage system, including I/O requests between data nodes, SnapTrim, Scrub, and Recovery.
The ZStack ZStone uses a weighted priority queue (wpq) to categorize and store the aforementioned I/O types into corresponding sub-queues. Each priority (prior) queue is created when its first request is enqueued. During dequeue, a weighted probability method determines the prior level. The priority (prior) of each queue serves as its weight. The probability of a prior queue being selected equals the ratio of its priority weight to the total weight of all queues. Even if selected, a prior queue is not guaranteed to dequeue a request; this also depends on the size of the request about to be dequeued.
- Low-Speed Recovery: Low-Speed Recovery gives a higher priority to the business bandwidth. The recovery time is relatively long. Any hardware failures during the recovery may reduce the data security level. We recommend that you choose Low-Speed Recovery in a production environment.
- Medium-Speed Recovery: Mid-Speed Recovery gives the same priority to the business bandwidth and recovery bandwidth. The recovery time is medium. A saturated performance may increase the I/O latency.
- High-Speed Recovery: High-Speed Recovery gives a higher priority to the recovery bandwidth. The recovery time is relatively short. A saturated performance may affect business performance.
Volume Business QoS
The ZStack ZStone supports configuring business QoS for block storage volumes, including maximum IOPS and maximum read/write bandwidth. By setting a business QoS, you can control the performance of different block storage volumes to meet diverse business performance requirements.
- The system generates tokens at a fixed rate and places them into a bucket. Every I/O request must acquire a token from this bucket.
- Requests that fail to acquire a token must queue to obtain one, thereby limiting the average data flow rate into the system.
- When the token distribution rate is slower than the token generation rate, tokens can accumulate in the bucket. This allows direct consumption of tokens from the bucket during short-term traffic bursts.
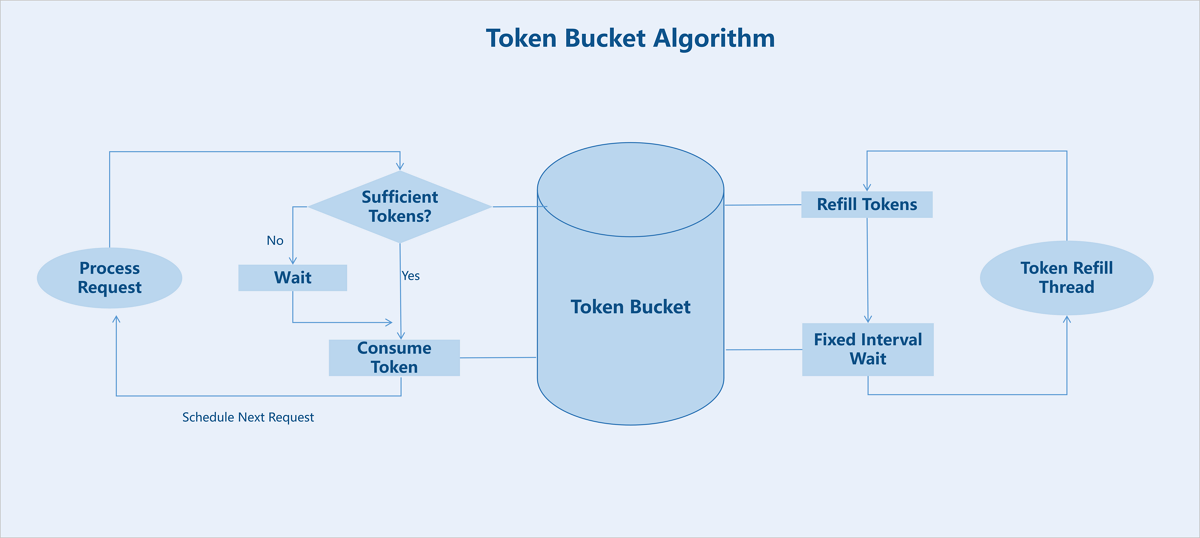
Data Protection
Volume Snapshot Protection
Snapshots serve as an important data protection mechanism in the ZStack ZStone. Snapshots allow users to create a complete state copy of a block storage volume at a specific point in time without interrupting services or impacting the production environment.
Snapshot Creation
The ZStack ZStone uses a COW (Copy-On-Write) snapshot technology. After creating a COW snapshot, the system creates a read-only copy of the original block device within the storage cluster. Data blocks are duplicated only when modifications occur in either the original device or the snapshot. This preserves the state of the original data in the snapshot while avoiding unnecessary data redundancy. The system also records the relationship between the original block device and the snapshot, as well as metadata information for each snapshot, such as creation time, size, and parent snapshot. Recording this metadata enables the system to accurately locate the specific snapshot state during data recovery.
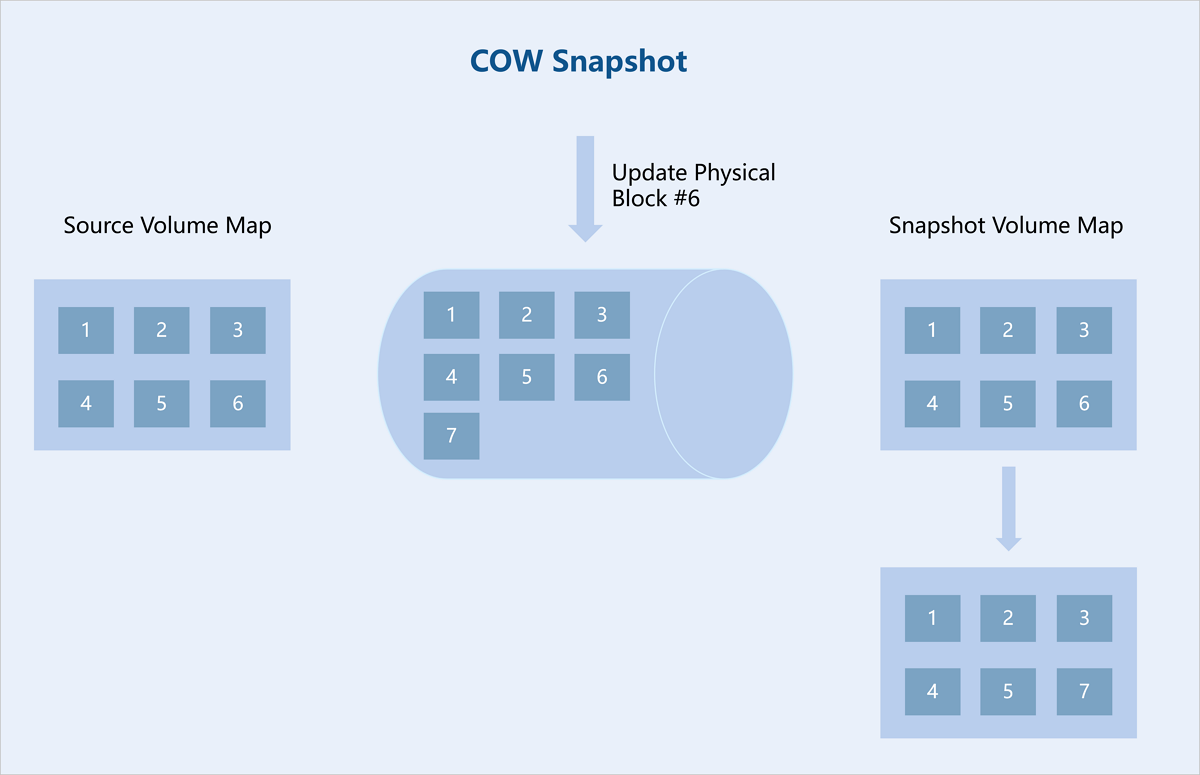
Data Rollback and Recovery
The ZStack ZStone supports creating new block storage volumes from snapshots, also known as cloning, where the new volume starts from the state of a specific snapshot. Additionally, in backup recovery or data rollback scenarios, you can revert a block storage volume to the state of a specified snapshot.
Data Redundancy
Overview
Data redundancy is the cornerstone for storage systems to achieve high availability, data protection, and business continuity. Faced with increasing data volumes, complex application scenarios, and potential risks such as hardware failures, network interruptions, and human errors, appropriate data redundancy policies provide you with a robust data protection barrier, ensuring business continuity and maximizing data value. This section briefly compares the characteristics of redundancy techniques in centralized storage and distributed storage, followed by a detailed explanation of the two core data protection policies adopted by the ZStack ZStone: replication and erasure coding (EC).
Centralized Storage vs. Distributed Storage
Centralized Storage
Traditional centralized storage uses controllers and disk enclosures to provide data management and read/write capabilities. It typically employs dual controllers for redundancy, while some high-end storage uses multiple controllers. Storage space is provided through the controller's built-in drive bays or externally connected expansion enclosures. Traditional centralized storage commonly uses RAID to protect data, such as RAID 5, RAID 6, or RAID 10.

Distributed Storage
Distributed storage adopts a decentralized architecture where each storage node provides computing and storage resources, enabling more flexible scalability and larger storage capacity. Storage nodes are interconnected via standard Ethernet switches and managed by the distributed storage software to provide a unified storage resource pool to upper-layer services. Furthermore, distributed storage supports horizontal scaling. A single cluster can expand to thousands of nodes to provide EB-level capacity, making it suitable for massive data storage scenarios.
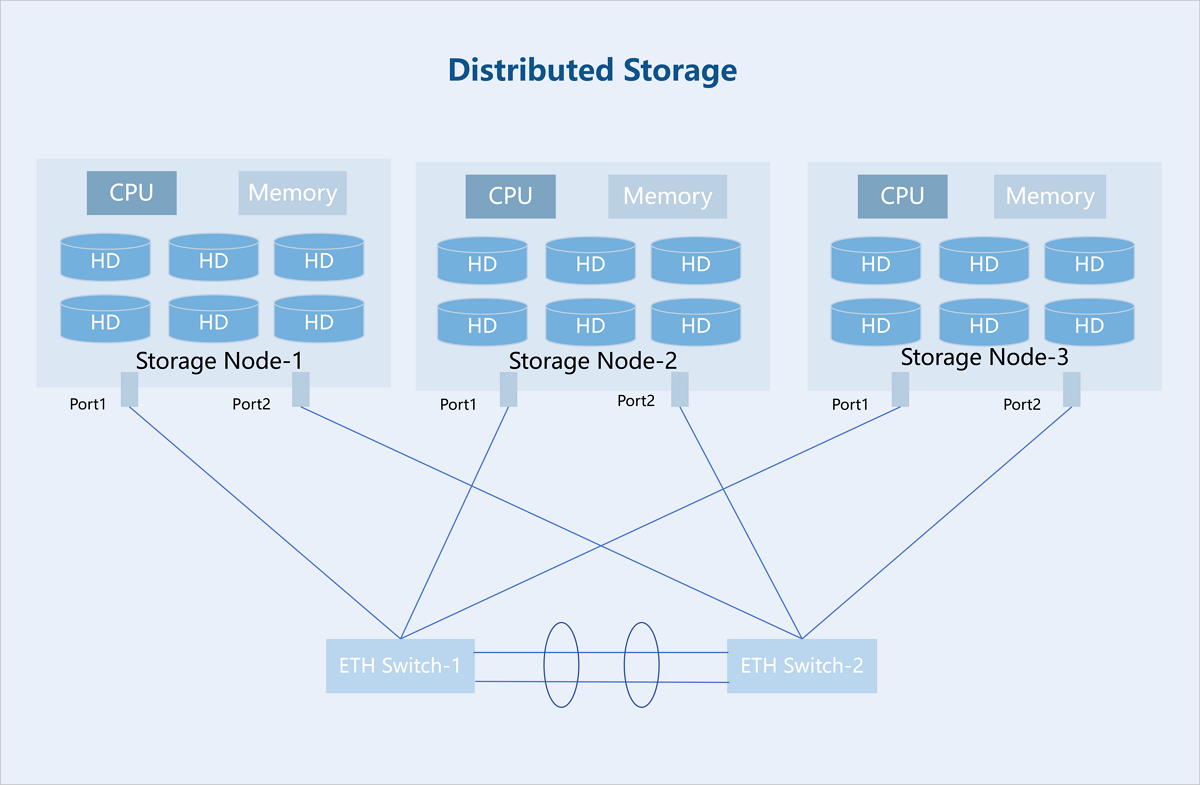
Centralized Storage vs. Distributed Storage
- Cross-Node Redundancy: Distributed storage supports redundancy across multiple nodes. For example, a three-replica policy can tolerate two nodes to fail simultaneously without data loss, whereas RAID only provides redundancy within a single node.
- Global Hot Spares and Data Recovery: Unlike RAID, which relies on the dedicated hot spare disk, distributed storage uses all available disks for data recovery, significantly improving efficiency. Additionally, distributed storage requires no additional hardware support, whereas RAID typically needs a dedicated RAID card.
Replication
Definition
Replication is a data protection technique that achieves data redundancy and high availability by storing the copies of the same data across different nodes. If a node fails, data can be recovered from the replicas on other nodes. You can configure 2 to 6 replicas, with 3 replicas recommended for production environments.
- Read/Write in Normal State
Taking a 3 replicas at the server level as an example: During data write, the system copies the data into three identical replicas and stores each on data disks in three different servers. During data read, the system reads the data from any one of the servers and returns it to the user.
Figure 3. Read/Write in Normal State with Three Replicas 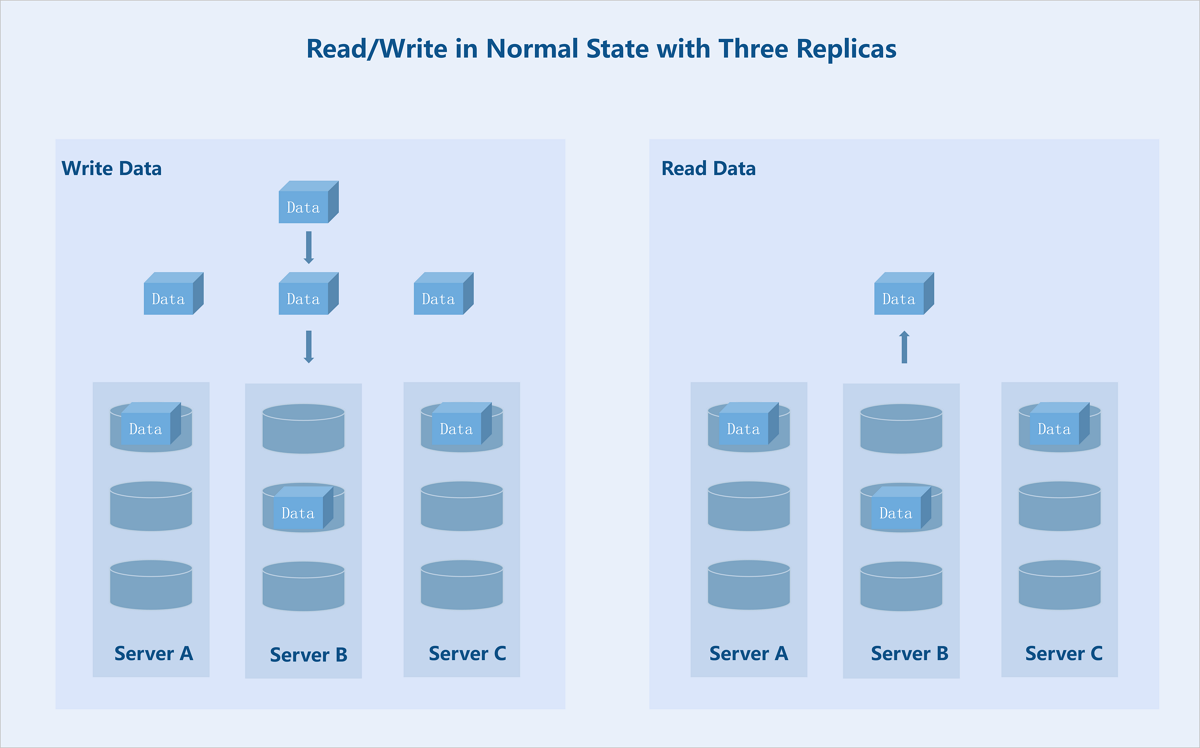
- Read/Write Under Failures
Taking a 3 replicas at the server level as an example: If server C fails, the system stores replicas on the remaining two servers. During data read, the system reads one replica from either of the remaining two servers and returns it to the user.
Figure 4. Read/Write Under Failures with Three Replicas 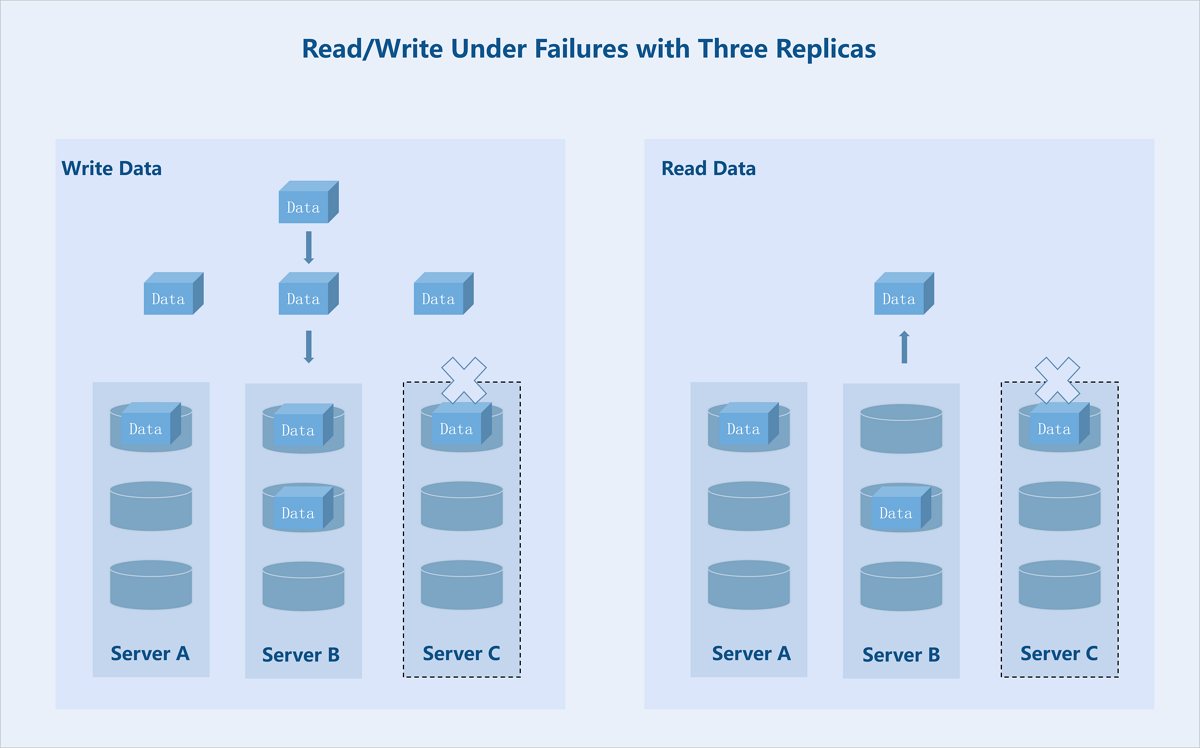
Erasure Coding (EC)
Overview
- Standard EC (K+M): K indicates the number of data blocks, and M indicates the number of parity blocks. This configuration tolerates simultaneous failures of M fault domains without affecting data availability.
- Folded EC (K+M:B): K indicates the number of data blocks, and M:B indicates the number of parity blocks. This configuration tolerates simultaneous failures of M hard disks or B fault domains without affecting data availability.
Policy Types
| EC Policy | Storage Efficiency | |
|---|---|---|
| Recommended Values | 2+1 | 66.67% |
| 4+2 | 66.67% | |
| 8+3 | 72.73% | |
| 4+2:1 | 66.67% | |
| 8+2:1 | 80.00% | |
| 16+2:1 | 88.89% | |
| Custom | K/(K+M) | |
Standard EC
- Read/Write in Normal State
Standard EC (K+M): Taking a server-level 4+2 EC policy as an example: During data write, the system splits the data into 4 equally sized data blocks and generates 2 parity blocks of the same size through the parity algorithm. The system randomly stores these 6 blocks across 6 servers. If any 2 servers fail, data remains accessible. During data read, the system reads data blocks from different data disks on 4 servers, assembles the 4 data blocks into complete data, and returns it to the user.
Figure 5. Data Write in Normal State with EC (4+2) 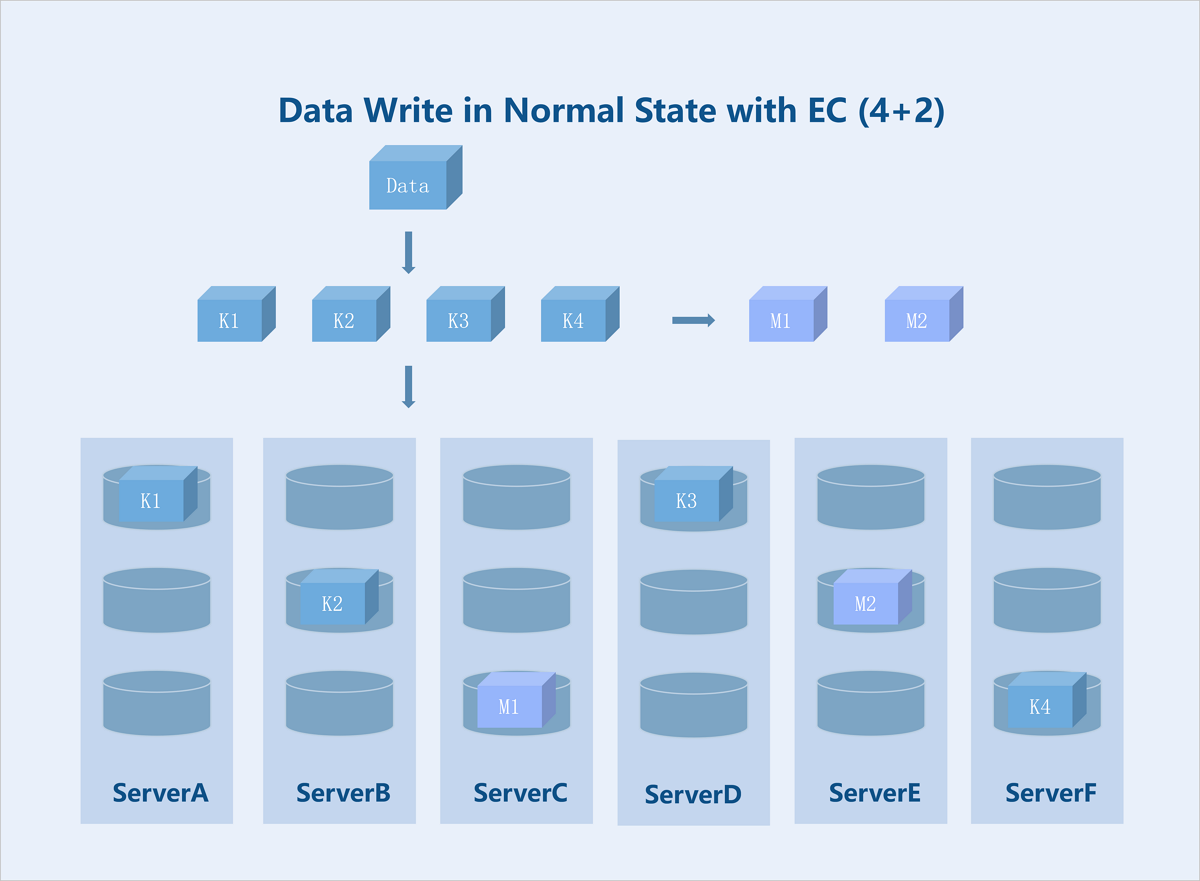
Figure 6. Data Read in Normal State with EC (4+2) 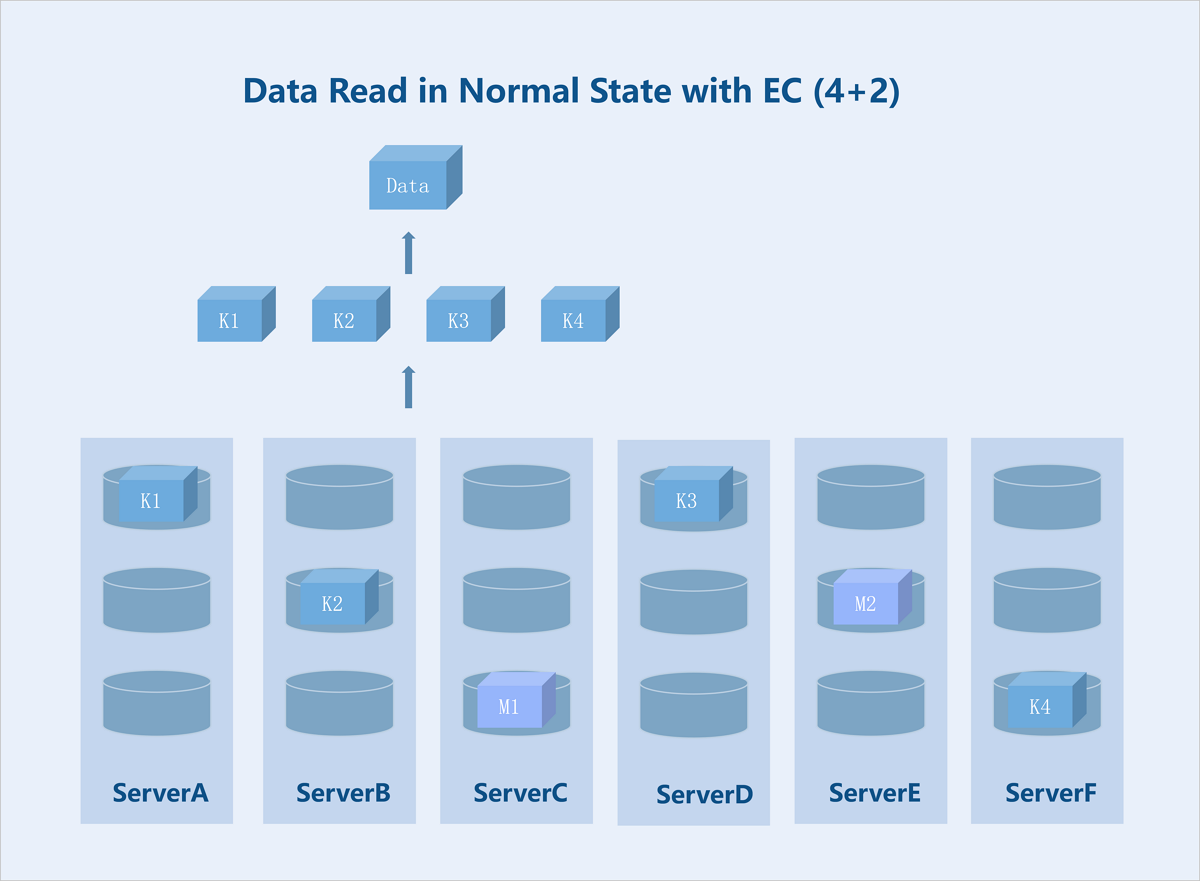
- Read/Write Under Failures
Standard EC (K+M): Taking a server-level 4+2 EC policy as an example: If the number of available servers drops below K+M due to failures, the system stores newly written data on the remaining servers before the recovery. This ensures I/O continuity without reducing the reliability. Once the failed servers recover, the data redundancy policy reverts to K+M. During data read, the system reads data from the remaining healthy servers and recovers the data using the parity algorithm before returning it to the user.
Figure 7. Data Write Under Failures with EC (4+2) 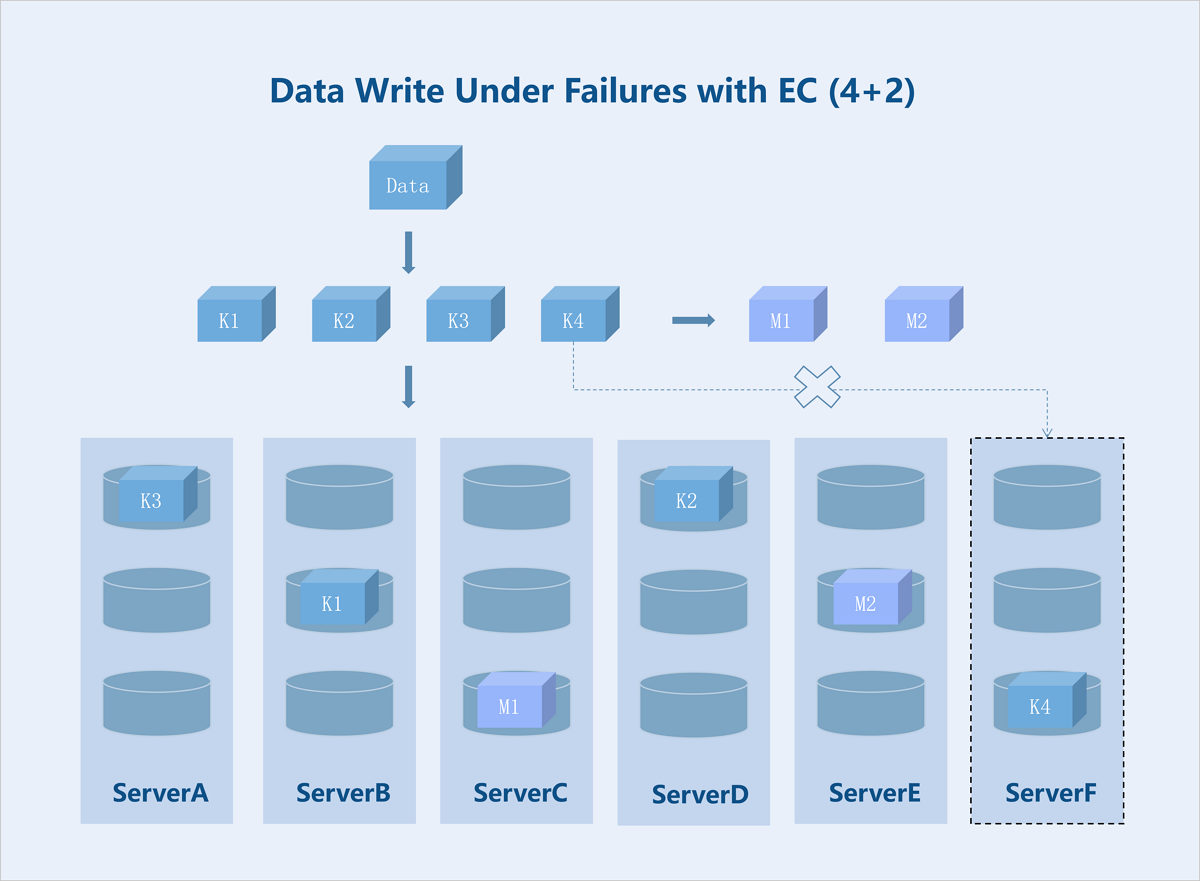
Figure 8. Data Read Under Failures with EC (4+2) 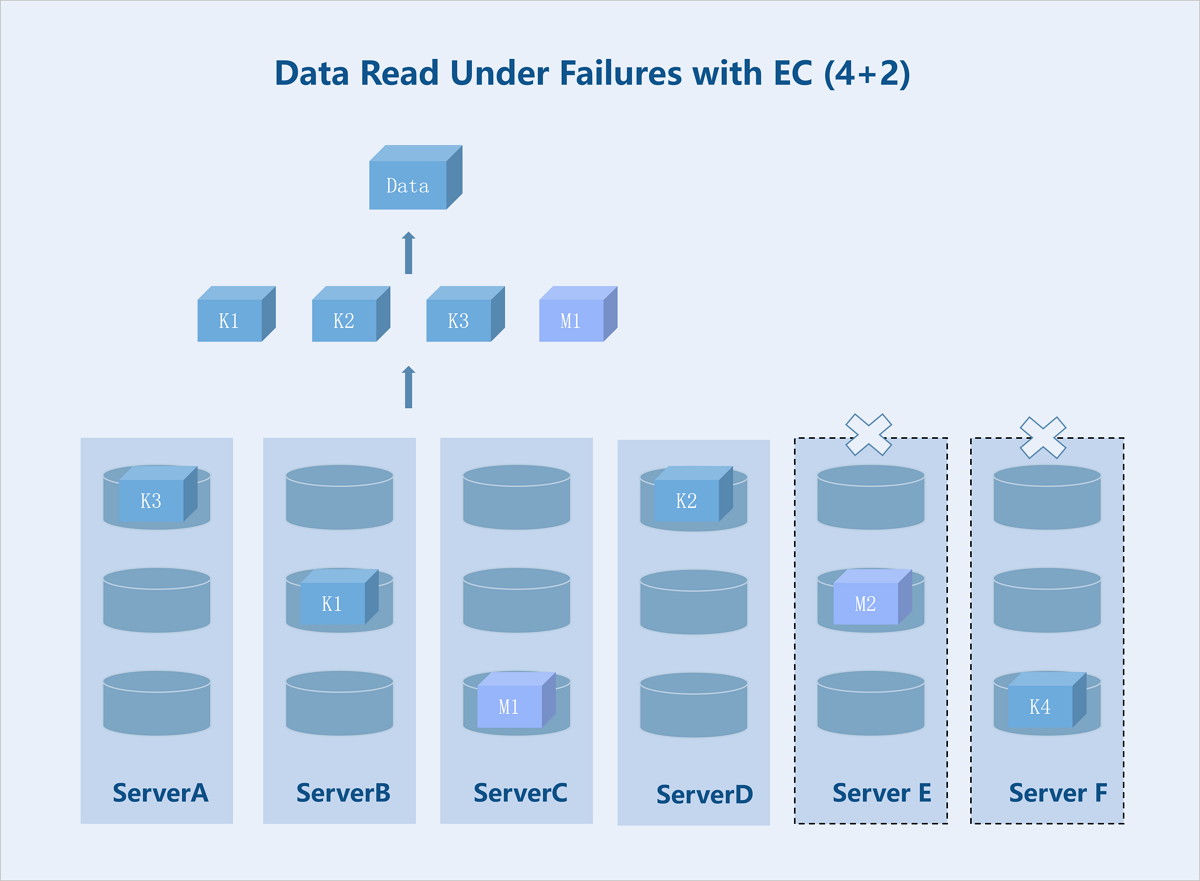
Folded EC
Folded EC, also known as sub-node EC, is another common data redundancy technique. Unlike the standard K+M EC configuration, the folded EC typically follows a K+M:B format, where B is usually set to 1. The folded EC maintains high data reliability while delivering improved storage efficiency.
For example, while a standard EC requires a minimum of 6 nodes, as its smallest fault domain is the storage node. A folded EC with 4+2:1 configuration can achieve data redundancy with as few as 3 storage nodes.
Furthermore, the folded EC supports scaling in and out just like standard EC. You can converts a folded EC to a standard EC as long as the fault domain requirements are met.
- Read/Write in Normal State
Folded EC (K+M:B): Taking a server-level 4+2:1 EC policy as an example: During data write, the system splits the data into 4 equally sized data blocks and generates 2 parity blocks of the same size through the parity algorithm. The system randomly stores these 6 blocks across 5 servers. If any one server fails, data remains accessible. During data read, the system reads data blocks from different data disks on 3 servers, assembles the 4 data blocks into complete data, and returns it to the user.
Figure 9. Data Write in Normal State with EC (4+2:1) 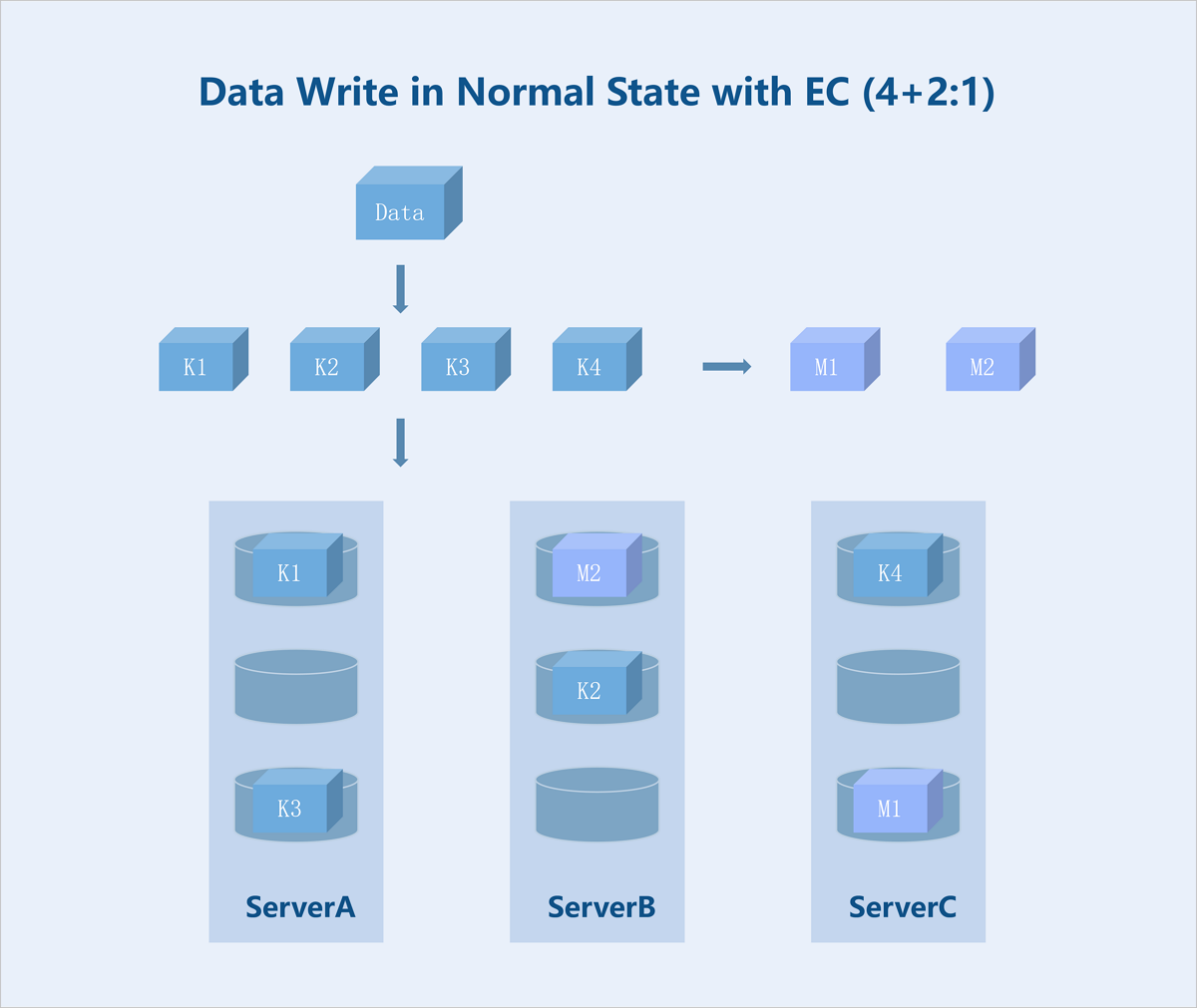
Figure 10. Data Read in Normal State with EC (4+2:1) 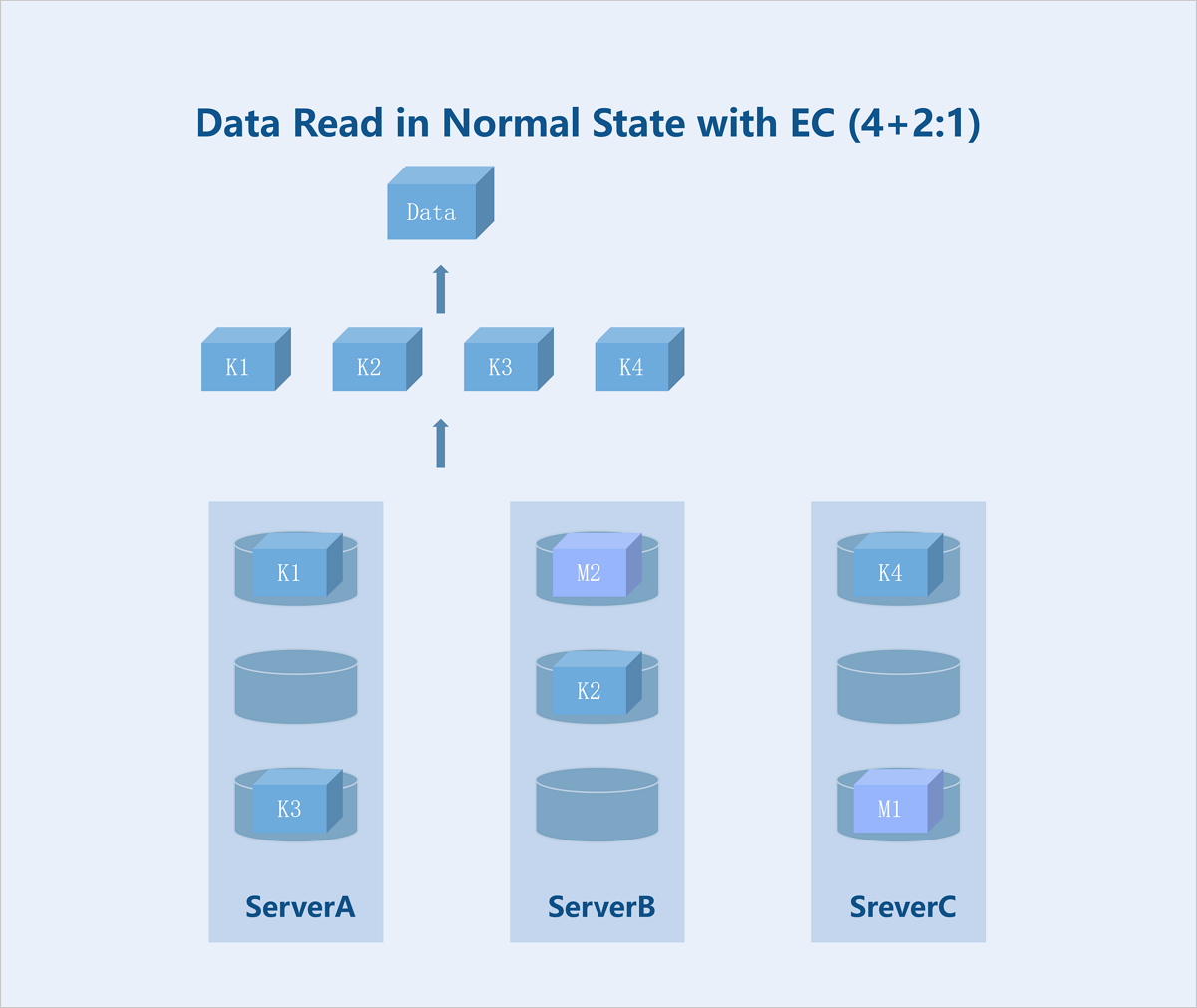
- Read/Write Under Failures
Folded EC (K+M:B): Taking a server-level 4+2:1 EC policy as an example: If one server or M hard disks fail, the system continues writing data and parity blocks to the remaining healthy servers according to the K+M configuration. During data read, the system reads data from other healthy servers and recovers the data using the parity algorithm before returning it to the user.
Figure 11. Data Read Under Failures with EC (4+2:1) 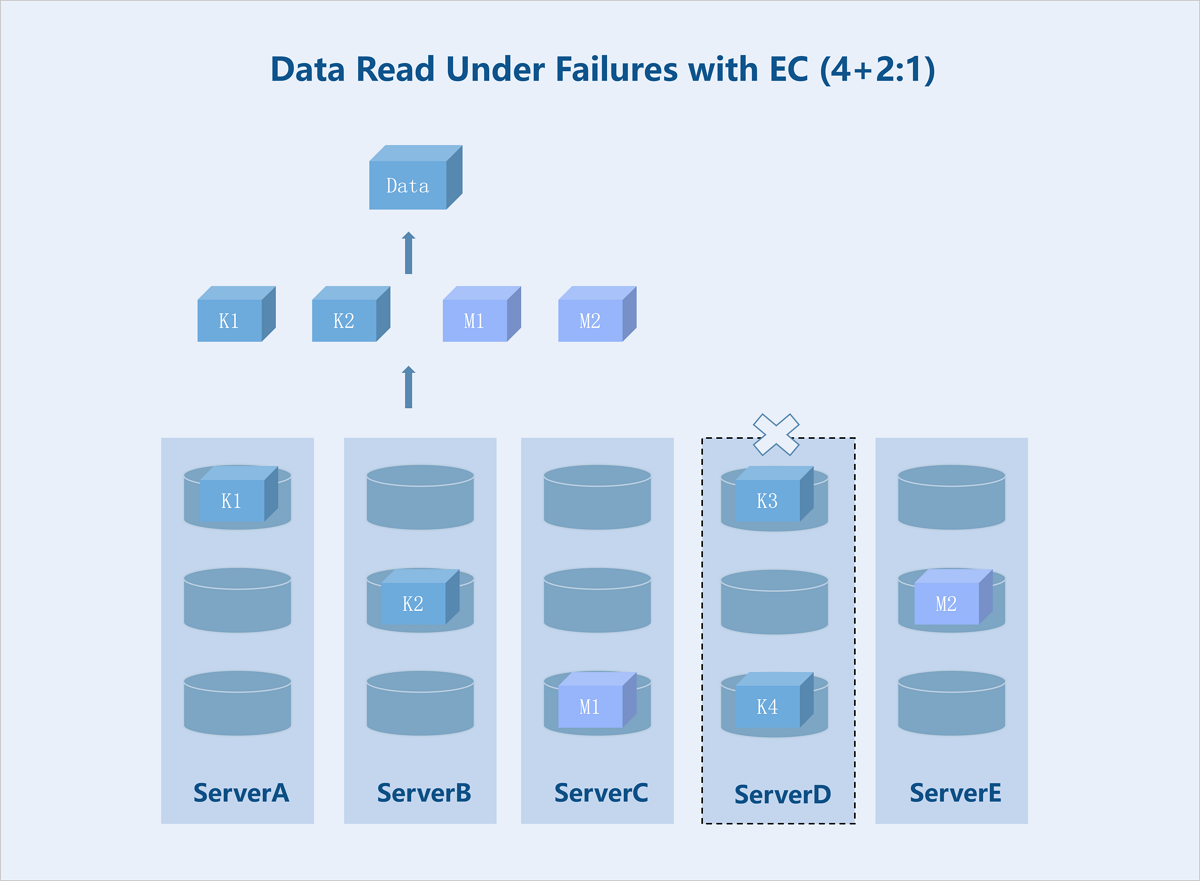
Replication vs. EC
- Storage Efficiency: EC holds a significant advantage. For example, a 4+2 EC policy offers approximately 66% effective storage, while 3 replicas policy achieves only 33.3%.
- Read/Write Performance: Performance varies significantly in small I/O scenarios. The gap narrows in large I/O scenarios. EC involves data validation during writes, which may introduce write amplification. During reads, performance can be impacted if any of the multiple nodes encountered high latency. In contrast, replication only needs to read one complete copy without any data reassembly
- Rebuild Performance: Replication generally outperformed EC in rebuild speed. Replication involves simple data copying without validation, resulting in faster rebuilds. EC rebuild requires reverse parity calculation, demanding more data I/O and higher CPU consumption.
- Fault Tolerance: Both policies have strengths and weaknesses. Replication allows up to (number of replicas − 1) simultaneous non-monitoring nodes failures without data loss. For EC, a 4+2 policy allows 2 simultaneous non-monitoring nodes failures without data loss.
Fault Domain Isolation
- Server-Level: Each server in the cluster acts as a fault domain. Different replicas or blocks of data are stored on different servers.
- Rack-Level: Each rack in the cluster acts as a fault domain. Different replicas or blocks of data are stored in different racks. Recommended for clusters of larger scale with more racks.
- Room-Level: Each room in the cluster acts as a fault domain. Different replicas or blocks of data are stored in different rooms. Recommended for very large clusters spanning multiple rooms.



Fault domain isolation helps contain the impact of failures to a specific scope, preventing a domino effect and thereby enhancing business continuity.
By leveraging fault domain-aware scaling along with rational storage policies, newly added nodes can form an independent disk pool without requiring data migration. This enables seamless capacity expansion, shielding applications from underlying storage changes and eliminating the need for application-level adjustments traditionally associated with storage updates. As a result, both operational and administrative workloads are significantly reduced, while system reliability and performance are enhanced.
Cluster Hardware Topology
The cluster topology provides a visual representation of the actual deployment of the cluster's physical resources. The topology includes logical entities such as data centers, rooms, racks, and servers, organized hierarchically in a tree structure to illustrate the distribution relationship from rooms down to servers. Each tree structure has a root node, and the cluster topology supports multiple root nodes. After planning the topology, you can select the corresponding level of data redundancy policy when creating a storage pool.
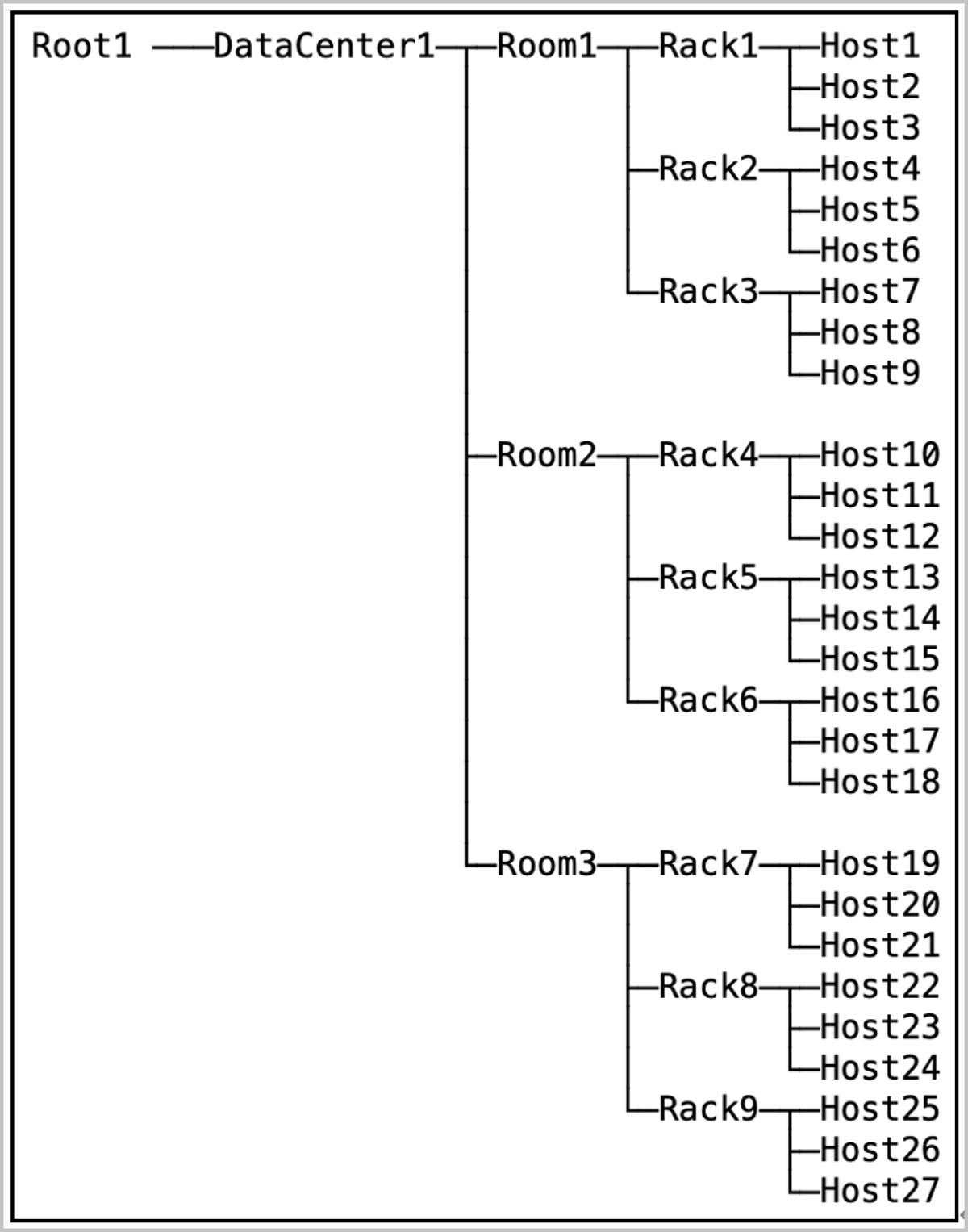
| Topology Object | Quantity Range |
|---|---|
| Data Center | 0~2 |
| Room | 0~100 (Per Data Center) |
| Rack | 0~100 (Per Room) |
| Server | 0~20 (Per Rack) |
Data Consistency Check
- Scrub Check: Focuses on metadata. It completes quickly and runs frequently. It is recommended to perform Scrub daily. You can customize the schedule.
- Deep-Scrub Check: Focuses on data. It takes longer to complete and may impact I/O performance. It is recommended to run during off-peak hours. An alert is triggered if no Deep-Scrub has been completed within 30 days.
Convenient O&M
Multiple Resource Pools
The ZStack ZStone supports multiple resource pools, helping you utilize storage media with different performance characteristics and achieve fault isolation.
Each resource pool has distinct attributes and performance, such as the number of replicas, data redundancy level, and storage media. You can flexibly allocate and manage resources based on actual requirements to improve storage efficiency and performance.
Resource pools are isolated from each other. You can implement data isolation management across multiple pools. Besides, failures in a single resource pool does not affect other resource pools, effectively safeguarding data security and storage reliability.
Hard Disk Light
The ZStack ZStone provides a visual interface to light on the hard disk for rapid locating. When you need to maintain or replace a disk, click Disk Light in the UI. The corresponding disk's LED indicator lights up in the physical environment, guiding you to quickly and accurately identify the device, thereby improving O&M efficiency.
Disk S.M.A.R.T. Monitoring
The ZStack ZStone supports S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) monitoring to track the health status, temperature, firmware, and total bytes written of disks. Upper-layer services trigger relevant alerts based on I/O errors and disk status information returned by the S.M.A.R.T. data.
Data Rebalancing
The ZStack ZStone supports data rebalancing to evenly distribute data across data disks under all storage servers in the cluster. This enhances storage system performance and reliability.
- Based on storage pool configurations and storage server load, the system automatically migrates data from overloaded nodes to those with lower load to achieve load balancing.
- When a server fails or a new server is added, the system automatically migrates data to maintain consistency and reliability.
Manual Data Rebalancing:
The system also supports manual data rebalancing. You can manually initiate rebalancing operations based on the actual data distribution.
Data Disk Maintenance Mode
The ZStack ZStone supports maintenance mode for data disks. To maintain servers or disks, you can put the corresponding disks into maintenance mode on the UI. A disk in this mode stops all services and data access, and the data on the disk does not undergo rebalancing.
Automatic Failure Detection and Alerting
The ZStack ZStone supports automatic failure detection and alerting. This mechanism monitors the storage platform system and individual storage servers. Upon detecting a failure, the system automatically sends alert messages to the platform. You can also add email endpoints to receive alarms, enabling timely response and recovery.
When a failure occurs, the system supports automatic service restart and data migration. This maximizes data reliability and availability, forming a highly reliable and highly available distributed storage system.
Product Integration
ZStack ZStone provides a RESTful management interface for seamless integration with upper-layer applications.
ZStack Cube Integration
Starting from version 4.2.0, ZStack ZStone supports integration with ZStack Cube, enabling unified monitoring and convenient scaling at the storage layer within ZStack Cube.
After integration, you can log into ZStack ZStone with one click and no password required via the ZStack Cube bootstrap or UI interface. You can directly view and use the storage services provided by ZStack ZStone and perform real-time monitoring and efficient management of storage resources.
ZStack Edge Integration
Starting from version 4.2.2, ZStack ZStone supports integration with ZStack Edge, enabling unified monitoring at the storage layer of ZStack Edge.
After integration, you can log into ZStack ZStone with one click and no password required via the ZStack Edge bootstrap or UI interface. You can directly view and use the storage services provided by ZStack ZStone and perform real-time monitoring and efficient management of storage resources.
Third-Party Storage Platform Integration
Starting from version 5.2.6, ZStack ZStone supports integration with third-party storage platforms, providing you with a unified entry for cross-platform resource management and monitoring.
You can enable the multi-platform addition option in global settings and complete the information configuration. After integration, you no longer need to frequently switch between different platforms, simplifying storage operation workflows and improving management efficiency.
Virtualization and Cloud-Native Platform Integration
ZStack ZStone ’s block storage service is primarily used for integration with virtualization platforms and cloud-native platforms, providing virtual block devices for upper-layer services.
Virtualization Platform
- Integration via Kernel-Mode Block Storage Interface:
The kernel-mode block storage interface runs in the host’s operating system kernel. This interface maps ZStack ZStone virtual volumes as block devices in the host’s OS, enabling QEMU to access block devices through this interface.
However, the kernel-mode block storage interface is not recommended for production deployment due to limited RBD feature support, strong dependency on the host’s OS kernel and high stability risks.
- Integration via User-Mode Block Storage Interface:
The user-mode block storage interface is a dedicated interface provided by ZStack ZStone for RBD block storage access, running in the user mode of the host’s OS. QEMU can use this interface to directly access ZStack ZStone block devices.
Virtualization platforms and the Cloud are recommended to use this scheme for integration with ZStack ZStone.
- Integration via SPDK + User-Mode Block Storage Interface:
SPDK is a high-performance user-mode storage stack development toolkit that works between QEMU and the user-mode block storage interface. QEMU can interact indirectly with the user-mode block storage interface through the vhost socket file provided by SPDK, thereby accessing ZStack ZStone block devices.
SPDK achieves high access speeds through kernel bypass and I/O polling techniques. However, because I/O requests are submitted directly to the hardware and completions are processed via polling, it introduces hardware resource contention, which can lead to issues such as I/O performance degradation.
Cloud-Native Platform
ZStack ZStone supports integration with cloud-native platforms centered on Kubernetes, providing block devices as persistent volumes for upper-layer container instances.
The integration of ZStack ZStone with cloud-native platforms primarily relies on CSI and CSI plugins. CSI is the standard container storage interface, and CSI plugins are applications that implement the CSI interface. CSI plugins run on multiple nodes in the cloud-native platform, providing control services and volume lifecycle management. These plugins can dynamically configure block devices provided by ZStack ZStone, mapping them as data volumes on the cloud-native platform, and mountig them to workloads to provide storage services.